Intelligent Name
Matching
In structured database, names are often treated the same as metadata for some other field like an email, phone number, or an ID number. But what happens if you only have a name to look up a record? This happens frequently, since humans tend to prefer names to numbers - and laws may prevent ID numbers from being created or shared.
When names are your only unifying data point, correctly matching similar names takes on a greater importance, however their variability and complexity make name matching a uniquely challenging task:
- Nicknames
- Translation errors
- Multiple spellings of the same name…
…can all result in missed matches.
While there is an abundance of search tools on the market, name search is a different animal than document search, and requires a fundamentally different approach.
Different name matching methods are best suited to solve different name matching challenges. There are many ways to match names, but no one universal solution. The best name matching software uses a hybrid of multiple methods to address the maximum number of name variations.
Each of these methods excels at solving one or several of the many challenges to accurate and consistent matching.
Common key method
- These methods reduce names to a key or code based on their English pronunciation, such that similar sounding names share the same key.
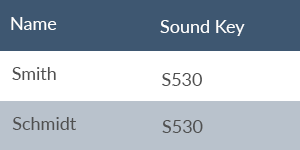
- A well-known common key method is Soundex, patented in 1918. For example, Cyndi, Canada, Candy, Canty, Chant, Condie share the code C530.
- Many methods take a similar approach to Soundex, including Metaphone and Double Metaphone. These methods use phonetic algorithms which turn similar sounding names into the same key, thus identifying similar names.
- Metaphone expands on Soundex with a wider set of English pronunciation rules and allowing for varying lengths of keys, whereas Soundex uses a fixed-length key.
- Double Metaphone further refines the matching by returning both a “primary” and “secondary” code for each name, allowing for greater ambiguity.
-
In addition, instead of being tied to English pronunciation of characters, it attempts to encompass pronunciations of other origins such as Slavic, Germanic, Celtic, Greek, French, Italian, Spanish, and Chinese.
-
For example, Double Metaphone encodes “Smith” with a primary code of SM0 and a secondary code of XMT, while it tags “Schmidt” with a primary code of XMT and a secondary code of SMT.
-
That the names share a primary and secondary code of XMT indicates a degree of similarity between the names which Soundex perhaps overstates and which Metaphone misses.
-
- Fast execution
- High recall
- Mostly limited to Latin-based languages; transliterating non-Latin names reduces precision

While the common key method is fast to execute and has good recall, the precision suffers. Manual inspection of a few names reveals the precision issues. These names share the Soundex key H245: Haugland, Hagelin, Haslam, Heislen, Heslin, Hicklin, Highland, Hoagland.
Metaphone does a better job than Soundex, encoding the above names with different codes, except for the very similar pairs Haugland/Hoagland and Heislen/Heslin.
For cases where name similarity is being scored against pairs of names in different scripts—for example Korean hangul vs. English—the name must first be converted to Latin characters, which potentially introduces more errors to the comparison. Particularly in languages such as Japanese where one character can have more than one correct pronunciations, converting first to the Latin script can introduce serious mistakes. The common Japanese female name洋子 can be correctly pronounced Yoko or Hiroko. Transliteration of names (a mapping of characters or sounds in one script to another) produces many possible variations since sounds in one language have to be approximated. Variations introduced by transliteration increases the complexity of the already difficult task of matching names. If عبد الرشید is being evaluated against Abdal-Rachid, but the transliteration of عبد الرشید produces Ar-Rashid, will the names come back as a match—as they should?


List method
Pros
- Fast execution
- High recall
- Computationally intensive (Expensive hardware needed to run against long lists of names quickly)
- Cannot handle names the system doesn’t know
- Cannot handle names with missing/added spaces between components
- Cannot handle names split between different fields
The List method attempts to list all possible spelling variations of each name component and then looks for matching names from these lists of name variations.
For example: One system produced 3 024 possible transliterations of this Arabic name “دیشرلا دبع “since each separate name component alone has several variations. Here are the first five and last five variations.
1. Abdal-rashid 2. Abdal-rashide 3. Abdal-rasheed 4. Abdal-rashiyd 5. Abdal-rachid … 3020. ‘Abd-errshiyd 3021. ‘Abd-errchid 3022. ‘Abd-errchide 3023. ‘Abd-errcheed 3024. ‘abd-errchiyd
Trying to generate every possible name variation has drawbacks, such as:
- Name variations that are not in the list will not be found as matches
- Speed & size issues: Since multipart names–particularly non-English names–generate an growing list of variations, searching through these lists takes time. Given a name with just three components and 20 possible variations per name, the number of possibilities is 203 (=8 000). This is a very large search space for just one name, now multiply it by the number of names on a watch list!
- Further challenges with the list method: How do you score matches when one of your 8 000 query variants matches more than one name in the database?
- It is difficult to handle other types of variation, like nicknames, initials, and titles, without expanding the search space even more.
A primary benefit of the list method is that it is simple to maintain.
- When a user complains about a missed match, it’s easily added to the name database.
- However, easy maintenance may not be enough to offset the decreased speed.
- For applications with that require high throughput over millions of names, such as
- Watchlist screening
- Anti-money laundering (AML)
- Know your customer (KYC)
this approach is likely to be too slow or require a lot of expensive hardware.
Edit Distance method
The Edit Distance approach looks at how many character changes it takes to get from one name to another.
For example: “Cindy” and “Cyndi” have an edit distance of 1, since the “i” and “y” are merely transposed, whereas “Catherine” and “Katharine” have an edit distance of 2 as the “C” turns into a “K” and the first “e” becomes an “a.”
How does the edit distance method work?
- Methods that look at the character-by-character distance between two names include:
- The Levenshtein distance
- The Jaro-Winkler distance
- The Jaccard similarity coefficient
- These approaches look at some combination of two factors (1) the number of similar characters and (2) the number of edit operations it takes to turn one name into the other. · Operations include insert, delete, and transpose.
NOTE: ALTHOUGH THESE COMPARISONS ARE QUICK, THEY DO NOT CAPTURE LINGUISTIC NUANCE.
- All edits are given the same weight. Thus changing “c” to “p” is weighted equally as “c” to “k” although in English the latter substitution might more clearly indicate a similar name, as in “Catherine” vs. “Katherine.”
- A one-to-many character mapping is not possible, as in the case of the Arabic character “sheen” ش which is frequently mapped to “sh” in English.
- As with the common key method, a non-Latin script name must first be transliterated to Latin script before the comparison can be executed, as explained in the discussion of “The Weakness of the Common Key Method in Matching Across Scripts”.
Statistical Similarity model
Pros
The Statistical Similarity approach takes hundreds, if not thousands, of matching name pairs and trains a model to recognise what two “similar names” look like, so that the model can take two names and assign a similarity score.
Benefits of statistical similarity
- A statistical model that has been trained on thousands of pairs of matching names offers high accuracy and the ability to directly match names written in different languages, without first transliterating names to Latin script.
- This method has a higher barrier to entry, as collecting the matching names requires significant resources.
- The accuracy that comes with this method, however, may be well worth the effort.
NOTE: A downside of this method is the slowness of execution. A system only using the statistical method to sift through millions of names to look for matches may be too slow to be feasible in high-transaction environments.
Word Embedding method for organisational and company names
Pros
Only relevant to organisation name matching:
- Organisation names differ from human names, in that variations may include synonyms that look and sound entirely different to the target name.
- In these cases, two names referring to one company are semantically similar but phonetically different. For example, a human can quickly infer that corporation, company, and group are all similar words often found in an organisation’s name, but standard name matching techniques like the edit distance method would be unlikely to make the connection. In these cases, word embeddings can make the match.
Word Embeddings are numerical vector representations of a word’s semantic meaning. If two words or documents have a similar embedding, they are semantically similar.
For example: The embeddings of “woman” and “girl” are close to one another in the vector space, meaning they are semantically similar. Contrastingly, the embeddings of “whale” and “philosophy” are far from one another because they are not semantically related.
Applied to organisations, the word embedding method recognises that Eagle Drugs and Eagle Pharmaceuticals are most likely the same company.
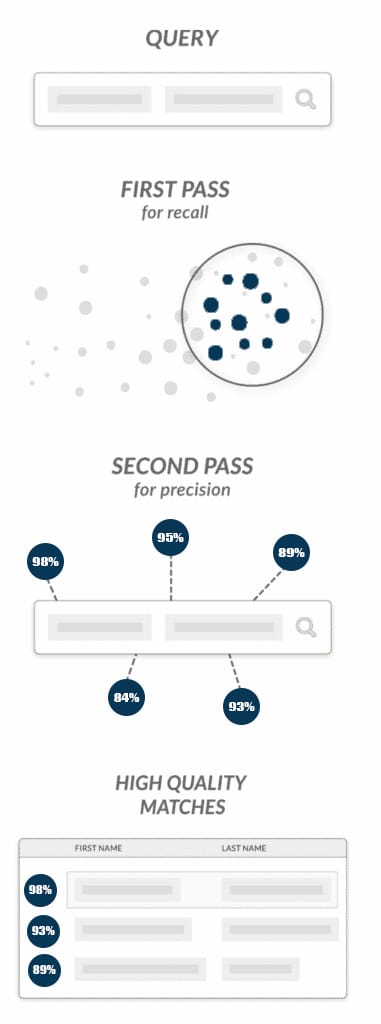
A two-pass, hybrid method: The Best of the Breed
Hybrid approaches backfill weakness in one approach with the strength of a different approach.
For example: A hybrid approach may first use the common key method for high recall, and then put its results through the statistical method for greater precision:
- In the first pass, the faster common key method and high recall narrows the candidate pool down to a smaller set of likely matches. This step is particularly vital when a list has names in different languages, first translating them, typically to English, before assigning metaphones.
- The second pass over the culled down list then uses a high-precision statistical method to filter the highest scoring matches to the top, making fine-grained distinctions between different matches.
Benefits of a hybrid approach:
- Compared to the common key method alone, accuracy is greatly improved by this hybrid method.
- Instead of being locked into a coarse comparison of derived keys (for better or worse), the second pass of the hybrid approach takes a fresh look at the original names in their original scripts before scoring their similarity.
- The hybrid method also avoids the weaknesses of the list approach by not relying on mass generation of name variations, but instead uses (via the statistical model) the linguistic variations of names in each language.
- This linguistic knowledge of name variations also gives the hybrid approach an edge over the edit distance method, which cannot directly compare names in different scripts. The result is a fast, accurate, name matching algorithm.